「Contextual Graph Embeddingsによる新しいデータ統合手法」に関するプレプリントを公開しました。
2025-11-13
- article
「Contextual Graph Embeddingsによる新しいデータ統合手法」に関するプレプリントをarxivに公開しました。
本研究では、異なるデータソースの統合におけるスキーママッチング(Schema Matching)やエンティティ解決(Entity Resolution)といったタスクを行う際に生じる構造のずれや表記ゆれといった課題に対し、データの構造(グラフ)と文脈情報(言語モデル)を組み合わせた新しい埋め込み手法を提案しました。
異種のデータ統合では、列名の表記ゆれや異なるスキーマ構造、欠損の多さなどが障壁となり、統合には多くの工数が必要です。従来のルールベースや知識ベースのアプローチは、ドメイン依存性が高く、複雑な異種のデータの構造情報を捉えることが困難でした。また、グラフニューラルネットワークは多ホップ関係を学習できる一方で、多数のラベル付きデータや膨大な調整が必要で、実務での利用には負荷が大きいという課題がありました。
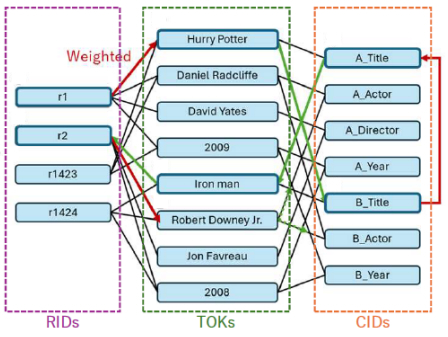
本研究では、これら従来手法の限界を踏まえ、異種データ統合のための新しい手法Contextual Graph Embeddingを提案し、実験によってその性能を評価しました。まず、行(RID)、列(CID)、セルの値(トークン)を結ぶ4部グラフを構築し、列名・説明文・統計量などの情報を統合して列同士の関係を表現します。学習では、グラフ構造上で列の重要度や類似度に応じた重み付きランダムウォークを行い、埋め込みを生成します。これにより、単なるトークン共起だけに依存せず、スキーマ構造や文脈情報を同時に反映する仕組みを実現しています。
実験では、データサイズ、欠損率、ドメイン固有性、列・行の重複率など、現実のデータに多く見られる特性を反映したデータに対して本手法を適用し、体系的に評価しました。実験の結果、提案手法は多様な条件で既存手法を上回り、特に欠損が多い場合や数値項目が中心のデータなど、従来手法が苦手とする場面で高い性能を発揮しました。一方で、列名が似ているが意味が異なるケースでは誤マッチが生じるなど、改善が必要な点も明らかになりました。
本研究は、構造と文脈を統合した新たなデータ統合手法を提案するとともに、これまで十分に扱われてこなかった、データの特性がマッチング性能に与える影響を定量的に評価したものです。今後は、類似度指標の高度化や専門家との半自動的なプロセスの設計を進め、実務でのデータ連携をより効率的かつ信頼性高く実現することを目指します。
https://arxiv.org/abs/2511.09001
タイトル:Contextual Graph Embeddings: Accounting for Data Characteristics in Heterogeneous Data Integration
著者:Yuka Haruki, Shigeru Ishikura, Kazuya Demachi, Teruaki Hayashi
アブストラクト:As organizations continue to access diverse datasets, the demand for effective data integration has increased. Key tasks in this process, such as schema matching and entity resolution, are essential but often require significant effort. Although previous studies have aimed to automate these tasks, the influence of dataset characteristics on the matching effectiveness has not been thoroughly examined, and combinations of different methods remain limited. This study introduces a contextual graph embedding technique that integrates structural details from tabular data and contextual elements such as column descriptions and external knowledge. Tests conducted on datasets with varying properties such as domain specificity, data size, missing rate, and overlap rate showed that our approach consistently surpassed existing graph-based methods, especially in difficult scenarios such those with a high proportion of numerical values or significant missing data. However, we identified specific failure cases, such as columns that were semantically similar but distinct, which remains a challenge for our method. The study highlights two main insights: (i) contextual embeddings enhance the matching reliability, and (ii) dataset characteristics significantly affect the integration outcomes. These contributions can advance the development of practical data integration systems that can support real-world enterprise applications.