「合成表データの意味的一貫性を評価する新指標」に関するプレプリントを公開しました。
2025-11-26
- article
「合成表データの意味的一貫性を評価する新指標」に関するプレプリントをarxivに公開しました。
合成データとは、現実世界の特徴を模倣した人工データのことです。合成データは実際の個人情報を含まずに、実際のデータと同じような振る舞いや特徴を有するように生成されます。そのため、プライバシーやデータ不足が問題視されている医療・金融・通信などの分野で利用が進みつつあり、信頼されるAI開発においても期待が高まっています。
一方で、合成データの性能評価においては課題がありました。相関やKLダイバージェンス、分類精度などの既存指標を用いれば、生成されたデータの分布や表面的な性能を測ることはできます。しかし、「合成データが実データで訓練したモデルと同じように振る舞うか」ということを評価することはできませんでした。そのため、合成データが分布上は実データに近い形状であっても、まったく異なるモデルを生成してしまっている危険があり、その結果、偏った分析や誤った判断につながる懸念がありました。
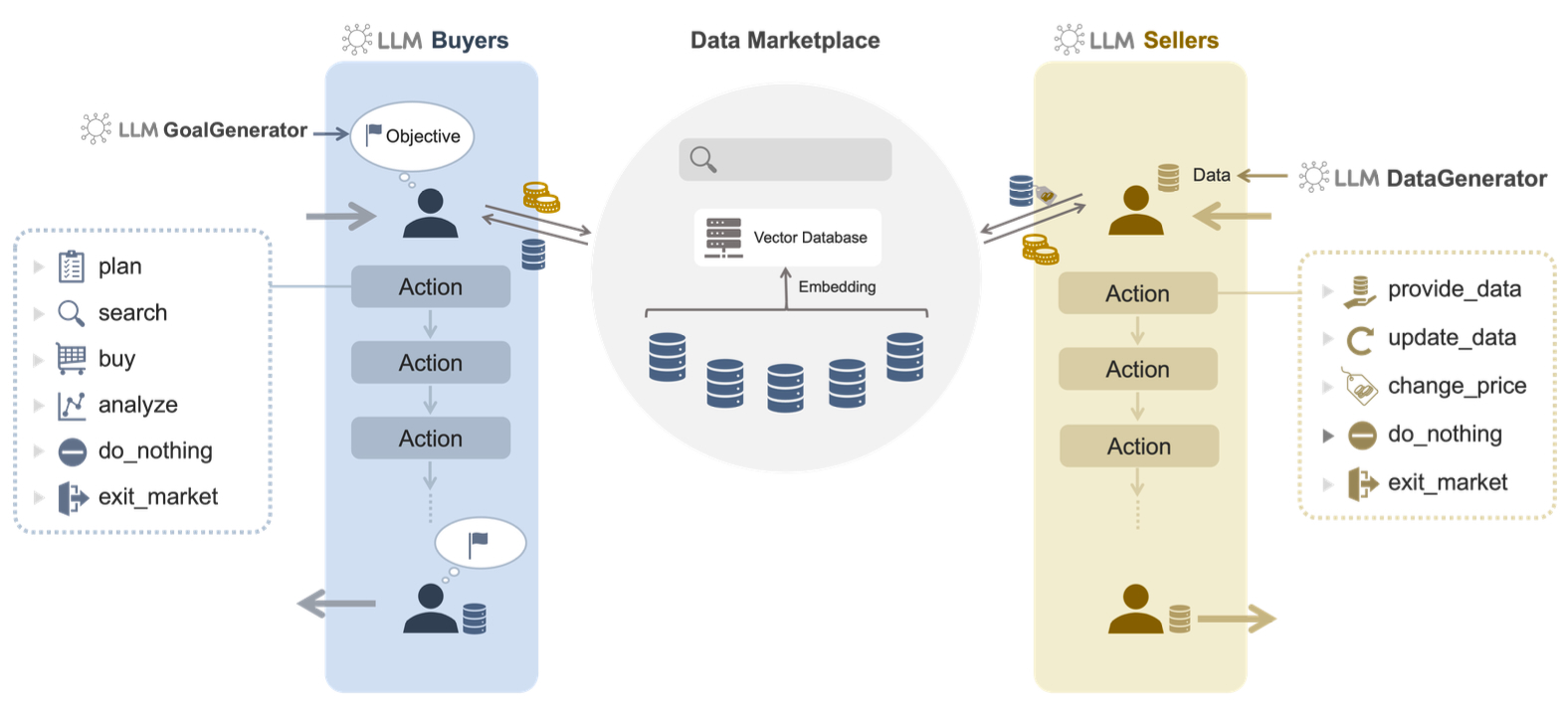
この課題に対し、本研究は合成された表形式のデータの評価のため、Explainable AIをベースとした新しい評価指標SHAP Distanceを提案しました。SHAP Distanceは、実データと合成データで学習したモデルの特徴量の重要度(SHAP値)のベクトルを直接比較する指標です。シンプルな設計でありながら、統計的類似度や精度では検出が難しい推論構造のズレを可視化できる点が特徴です。
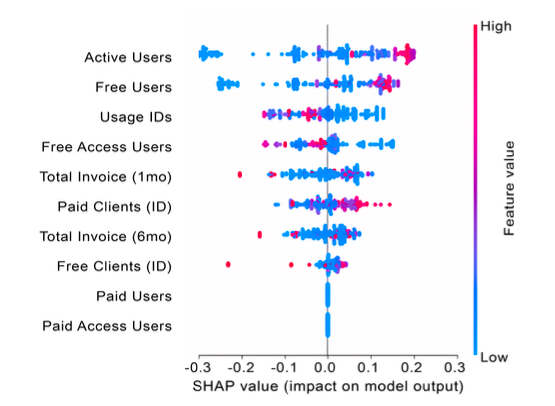
実験では、UCI Heart Disease、企業請求データ、Telco Churnの3つの異なる領域の表形式データを対象に検証を行いました。合成データは中央傾向を模倣しやすい一方で、尾部の振る舞いや複雑な非線形関係の再現が弱いことが分かりました。また、重要な特徴の順位付けや交互作用を比較した結果、分布が似ていても説明力が異なるケースが確認されました。また、興味深いのは、SHAP Distanceが小さい合成データは、統計的な差異があっても、実データに最も近い分析性能を示した点です。これは「合成データの実用性は統計的な類似度ではなく、意味の一貫性に依存する」可能性があるという重要な示唆となります。合成データが実務の意思決定や学習タスクに利用される場面が増える中、このような特徴を捉える評価方法は重要となります。
本研究は、合成データ評価における分布、性能に続く第三の軸としてSemantic Fidelity(意味的一貫性)を加え、合成表形式データの新たな品質評価の方向性を提示しました。今後は、合成データ内の因果関係や高次元データ・時系列データへの応用、生成プロセスにSHAP Distanceを組み込む自動改善ループなど、より高度な合成データの品質保証技術への発展を目指していきます。
https://arxiv.org/abs/2511.17590
タイトル:SHAP Distance: An Explainability-Aware Metric for Evaluating the Semantic Fidelity of Synthetic Tabular Data
著者:Ke Yu, Shigeru Ishikura, Yukari Usukura, Yuki Shigoku, Teruaki Hayashi
アブストラクト:Synthetic tabular data, which are widely used in domains such as healthcare, enterprise operations, and customer analytics, are increasingly evaluated to ensure that they preserve both privacy and utility. While existing evaluation practices typically focus on distributional similarity (e.g., the Kullback-Leibler divergence) or predictive performance (e.g., Train-on-Synthetic-Test-on-Real (TSTR) accuracy), these approaches fail to assess semantic fidelity, that is, whether models trained on synthetic data follow reasoning patterns consistent with those trained on real data. To address this gap, we introduce the SHapley Additive exPlanations (SHAP) Distance, a novel explainability-aware metric that is defined as the cosine distance between the global SHAP attribution vectors derived from classifiers trained on real versus synthetic datasets. By analyzing datasets that span clinical health records with physiological features, enterprise invoice transactions with heterogeneous scales, and telecom churn logs with mixed categorical-numerical attributes, we demonstrate that the SHAP Distance reliably identifies semantic discrepancies that are overlooked by standard statistical and predictive measures. In particular, our results show that the SHAP Distance captures feature importance shifts and underrepresented tail effects that the Kullback-Leibler divergence and Train-on-Synthetic-Test-on-Real accuracy fail to detect. This study positions the SHAP Distance as a practical and discriminative tool for auditing the semantic fidelity of synthetic tabular data, and offers practical guidelines for integrating attribution-based evaluation into future benchmarking pipelines.