Preprint Published on "Reputation System Design for Manufacturing Data Markets"
2025-12-06
- article
We have released a new preprint on arXiv about "Designing Reputation Systems for Manufacturing Data Trading Markets."
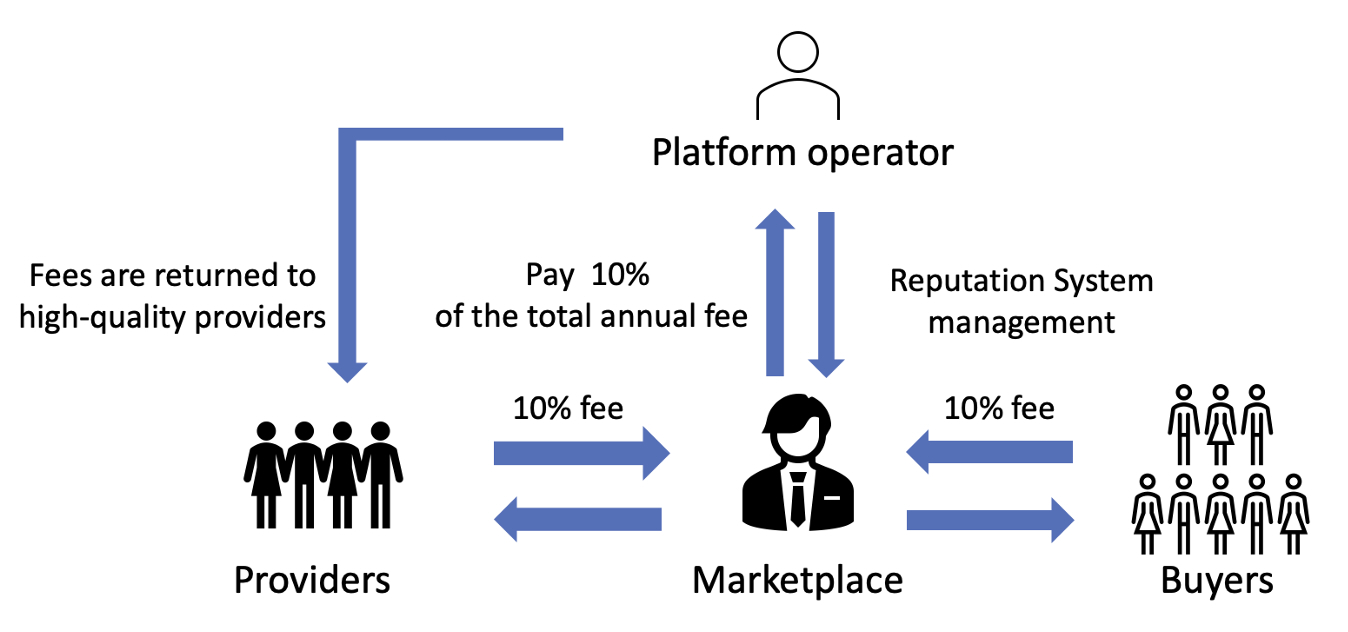
As AI and machine learning continue to advance, the volume of inter-organizational data trading has grown rapidly. However, due to the inherent nature of data, it is often impossible to fully assess data quality prior to purchase. This raises a fundamental question: can buyers reliably obtain trustworthy data from trustworthy providers? To address this challenge, our study focuses on reputation systems as a mechanism for trust formation in data trading markets. In particular, we investigate their effectiveness in markets dealing with manufacturing data using a multi-agent simulation framework.
In our simulation, data providers and buyers are modeled as autonomous agents that repeatedly make decisions within the market. Providers and buyers update their strategies through reinforcement learning (Q-learning), while buyers’ evaluation criteria (utility functions) are estimated from real behavioral data using inverse reinforcement learning. This allows us to construct a market model that more closely reflects real-world decision-making processes than conventional approaches.
Using this simulation environment, we compared five representative reputation systems—Time-decay, Bayesian-beta, PageRank, PowerTrust, and PeerTrust. Our results show that PeerTrust most effectively enhances the consistency between price and data quality (accuracy, coverage, freshness, and compliance) while also improving overall market stability. Because manufacturing applications place high importance on data reliability and compliance, these findings suggest that multi-factor reputation models like PeerTrust are especially advantageous.
Building on these insights, we further propose a new hybrid reputation system called Beta-PT, which integrates the strengths of PeerTrust and Bayesian-beta. This model reduces the disproportionate influence of overly active reviewers and achieves the highest alignment between price and quality among all tested methods. In other words, it provides a promising mechanism for creating markets in which high-quality data are correctly valued and traded at fair prices.
This study contributes to the broader question of how to design trust-based data ecosystems in an era where data sharing is becoming increasingly essential. The proposed methods have potential applications not only in manufacturing but also in fields such as healthcare, finance, and IoT platforms, where data reliability is critical. Moving forward, we plan to extend our framework by incorporating more complex market behaviors and adversarial participants, ultimately contributing to the institutional design of next-generation data markets.
https://arxiv.org/abs/2511.19930
Title: Designing Reputation Systems for Manufacturing Data Trading Markets: A Multi-Agent Evaluation with Q-Learning and IRL-Estimated Utilities
Authors: Kenta Yamamoto, Teruaki Hayashi
Abstract: Recent advances in machine learning and big data analytics have intensified the demand for high-quality cross-domain datasets and accelerated the growth of data trading across organizations. As data become increasingly recognized as an economic asset, data marketplaces have emerged as a key infrastructure for data-driven innovation. However, unlike mature product or service markets, data-trading environments remain nascent and suffer from pronounced information asymmetry. Buyers cannot verify the content or quality before purchasing data, making trust and quality assurance central challenges. To address these issues, this study develops a multi-agent data-market simulator that models participant behavior and evaluates the institutional mechanisms for trust formation. Focusing on the manufacturing sector, where initiatives such as GAIA-X and Catena-X are advancing, the simulator integrates reinforcement learning (RL) for adaptive agent behavior and inverse reinforcement learning (IRL) to estimate utility functions from empirical behavioral data. Using the simulator, we examine the market-level effects of five representative reputation systems-Time-decay, Bayesian-beta, PageRank, PowerTrust, and PeerTrust-and found that PeerTrust achieved the strongest alignment between data price and quality, while preventing monopolistic dominance. Building on these results, we develop a hybrid reputation mechanism that integrates the strengths of existing systems to achieve improved price-quality consistency and overall market stability. This study extends simulation-based data-market analysis by incorporating trust and reputation as endogenous mechanisms and offering methodological and institutional insights into the design of reliable and efficient data ecosystems.