Preprint Published on "A Novel Metric for Evaluating the Semantic Fidelity of Synthetic Tabular Data."
2025-11-26
- article
We have released a new preprint on arXiv introducing a novel metric for evaluating the semantic fidelity of synthetic tabular data.
Synthetic data are artificially generated datasets that mimic the characteristics and statistical properties of real-world data without containing any actual personal information. Because they reproduce realistic behaviors while safeguarding privacy, synthetic data are increasingly used in domains such as healthcare, finance, and telecommunications—fields where data scarcity and privacy concerns are particularly critical. They are also gaining attention as a foundation for trustworthy AI development.
However, evaluating the quality of synthetic data has long faced a methodological gap. Existing metrics, such as correlations, KL divergence, or classification accuracy, can measure distributional similarity or surface-level performance, but they cannot assess whether models trained on synthetic data behave in the same way as models trained on real data. As a result, even if a synthetic dataset appears statistically similar to the real one, it may still lead to models that rely on entirely different logic, potentially causing biased analyses or misleading conclusions.
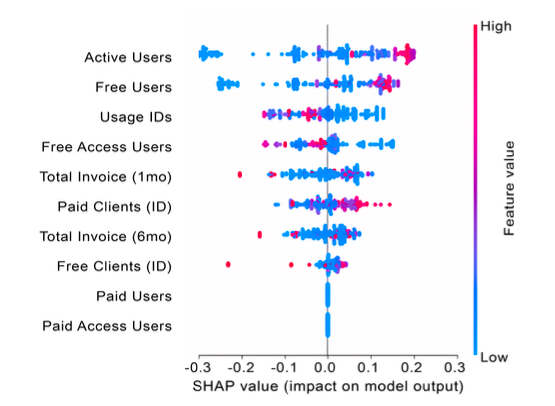
To address this challenge, our study proposes a new evaluation metric, SHAP Distance, grounded in Explainable AI (XAI). SHAP Distance directly compares the feature attribution vectors (SHAP values) obtained from models trained on real versus synthetic data. Despite its simple formulation, it can reveal discrepancies in reasoning processes that distributional measures or accuracy metrics fail to capture.
We validated the metric across three tabular datasets—UCI Heart Disease, enterprise invoice data, and Telco Churn. The results show that while synthetic data often replicate central tendencies well, they struggle to reproduce tail behaviors and complex nonlinear interactions. Additionally, even when the overall distributions appear similar, the explanatory structure of models can differ. Notably, synthetic data with a low SHAP Distance achieved the closest analytical performance to real data, even when statistical differences remained. This finding suggests that the practical usefulness of synthetic data may depend more on semantic consistency than on superficial statistical similarity—a perspective that becomes increasingly important as synthetic data are adopted in real-world decision-making and machine learning workflows.
By introducing Semantic Fidelity as a third axis of evaluation—alongside distributional similarity and predictive performance—this research provides a new direction for quality assessment in synthetic tabular data. Future work will explore extensions to causal structures within synthetic data, applications to high-dimensional and temporal datasets, and the integration of SHAP Distance into self-improving generative loops, advancing the development of robust and trustworthy synthetic data generation frameworks.
https://arxiv.org/abs/2511.17590
Title: SHAP Distance: An Explainability-Aware Metric for Evaluating the Semantic Fidelity of Synthetic Tabular Data
Authors: Ke Yu, Shigeru Ishikura, Yukari Usukura, Yuki Shigoku, Teruaki Hayashi
Abstract: Synthetic tabular data, which are widely used in domains such as healthcare, enterprise operations, and customer analytics, are increasingly evaluated to ensure that they preserve both privacy and utility. While existing evaluation practices typically focus on distributional similarity (e.g., the Kullback-Leibler divergence) or predictive performance (e.g., Train-on-Synthetic-Test-on-Real (TSTR) accuracy), these approaches fail to assess semantic fidelity, that is, whether models trained on synthetic data follow reasoning patterns consistent with those trained on real data. To address this gap, we introduce the SHapley Additive exPlanations (SHAP) Distance, a novel explainability-aware metric that is defined as the cosine distance between the global SHAP attribution vectors derived from classifiers trained on real versus synthetic datasets. By analyzing datasets that span clinical health records with physiological features, enterprise invoice transactions with heterogeneous scales, and telecom churn logs with mixed categorical-numerical attributes, we demonstrate that the SHAP Distance reliably identifies semantic discrepancies that are overlooked by standard statistical and predictive measures. In particular, our results show that the SHAP Distance captures feature importance shifts and underrepresented tail effects that the Kullback-Leibler divergence and Train-on-Synthetic-Test-on-Real accuracy fail to detect. This study positions the SHAP Distance as a practical and discriminative tool for auditing the semantic fidelity of synthetic tabular data, and offers practical guidelines for integrating attribution-based evaluation into future benchmarking pipelines.