Preprint Published on M2 Student Haruki’s Research on a Data Quality Assessment Tool.
2025-04-10
- news
- research

We have released a preprint on arXiv for a paper titled "Development of a Data Quality Assessment Tool and Feature Analysis by Evaluation Index" by M2 student Ms. Haruki.
This study, conducted in collaboration with Kyodo Printing Co., Ltd., focuses on the development of an automated tool to support Data Quality Assessment (DQA), which is essential for data trading and exchange.
As data becomes an increasingly valuable business resource, companies and local governments are turning to external data sources for decision-making and service improvement. However, assessing the quality of such data requires expert knowledge, and evaluations often vary depending on the person in charge, posing a challenge for fair and consistent data utilization.
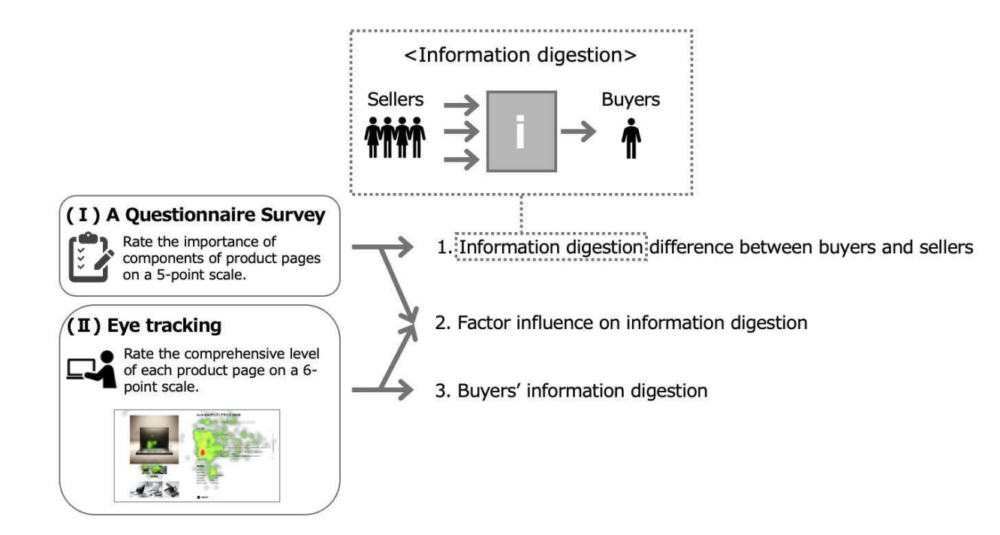
In this research, the team developed a tool that automatically generates quality metadata using ten evaluation indices, such as accuracy, completeness, and rarity, providing a visual and intuitive means to understand data quality. The effectiveness of the tool was verified through a questionnaire involving 41 working professionals, as well as an eye-tracking experiment to observe cognitive behavior during evaluation.
The findings revealed that the tool significantly improved evaluation accuracy among experienced data analysts and helped reduce incorrect judgments. However, semi-experienced users tended to rate the tool lower, often due to the overwhelming volume of information, which also led to greater variability in their assessments.
This research is expected to contribute to more objective and efficient decision-making in real-world data trading and exchange by reducing subjectivity in data evaluation processes.
https://doi.org/10.48550/arXiv.2504.02663
Title: Development of Automated Data Quality Assessment and Evaluation Indices by Analytical Experience
Authors: Yuka Haruki, Kei Kato, Yuki Enami, Hiroaki Takeuchi, Daiki Kazuno, Kotaro Yamada, Teruaki Hayashi
Abstract: The societal need to leverage third-party data has driven the data-distribution market and increased the importance of data quality assessment (DQA) in data transactions between organizations. However, DQA requires expert knowledge of raw data and related data attributes, which hinders consensus-building in data purchasing. This study focused on the differences in DQAs between experienced and inexperienced data handlers. We performed two experiments: The first was a questionnaire survey involving 41 participants with varying levels of datahandling experience, who evaluated 12 data samples using 10 predefined indices with and without quality metadata generated by the automated tool. The second was an eye-tracking experiment to reveal the viewing behavior of participants during data evaluation. It was revealed that using quality metadata generated by the automated tool can reduce misrecognition in DQA. While experienced data handlers rated the quality metadata highly, semi-experienced users gave it the lowest ratings. This study contributes to enhancing data understanding within organizations and promoting the distribution of valuable data by proposing an automated tool to support DQAs.