Preprint Published on "Explainability of Reliable Large Language Models toward Generating Trustworthy Explanations."
2025-11-06
- article
We have released a preprint on arXiv titled “Explainability of Large Language Models: Opportunities and Challenges toward Generating Trustworthy Explanations.”
This study focuses on the explainability of Large Language Models (LLMs), which have recently attracted significant attention, and proposes a theoretical and empirical framework to enhance their reliability and effectiveness.
As generative AI technologies are increasingly applied to critical domains such as healthcare and autonomous driving, it has become urgent to ensure that users can understand why an AI system produced a particular output and trust its reasoning. However, LLMs remain complex and opaque in their internal structures, making it difficult to trace the rationale behind their outputs.
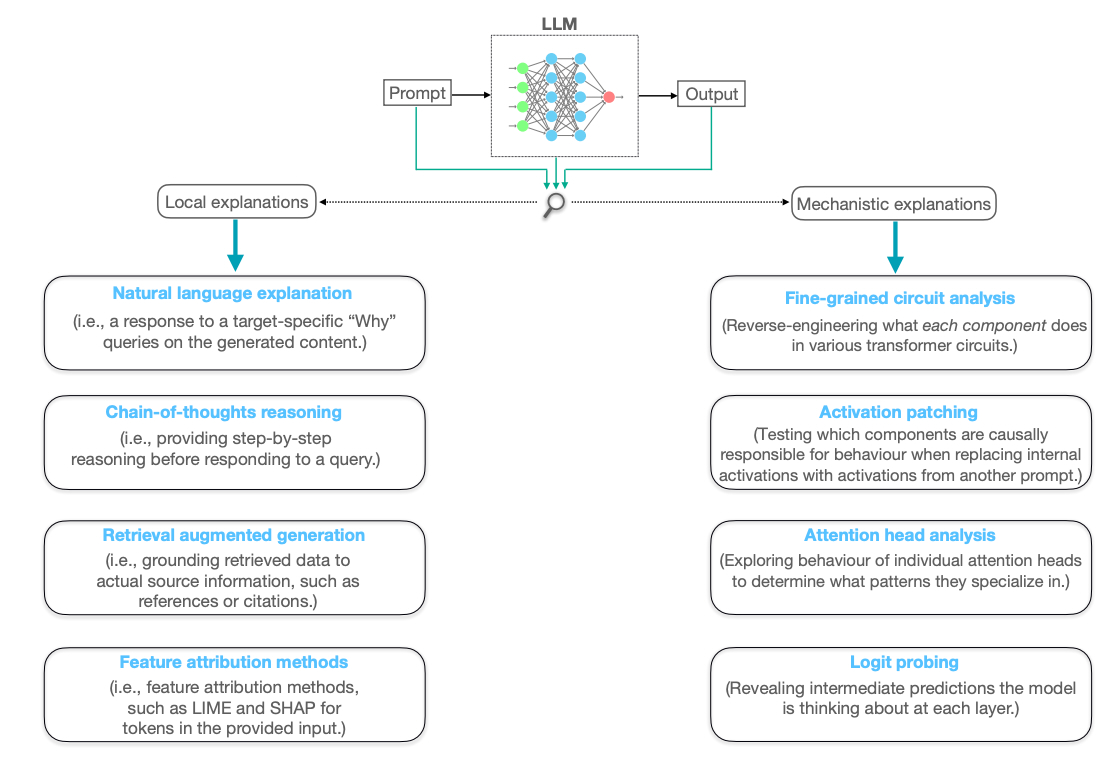
To address this issue, our study systematically organizes the mechanisms of explanation generation and trust formation in LLMs from two complementary perspectives: local explainability, which seeks to clarify the reasoning behind specific outputs, and mechanistic interpretability, which aims to analyze the internal workings of the model itself.
Furthermore, by examining high-stakes application areas such as healthcare and autonomous driving, we analyze how different forms of explanations affect users’ understanding and trust, demonstrating that the faithfulness and explicitness of explanations are critical for building reliable human–AI relationships.
This research provides a methodology for enhancing the transparency and accountability of AI systems, and proposes new directions for implementing Explainable AI (XAI). Future work will advance model visualization techniques and the standardization of explanation evaluation, contributing to the realization of socially trustworthy AI.
This work was conducted in collaboration with members of the XAI Lab at the University of Alberta during Dr. Hayashi’s appointment as a Visiting Professor. We invite you to read the full paper on arXiv.
https://arxiv.org/abs/2510.17256
Title: Explainability of Large Language Models: Opportunities and Challenges toward Generating Trustworthy Explanations
Authors: Shahin Atakishiyev, Housam K.B. Babiker, Jiayi Dai, Nawshad Farruque, Teruaki Hayashi, Nafisa Sadaf Hriti, Md Abed Rahman, Iain Smith, Mi-Young Kim, Osmar R. Zaïane, Randy Goebel
Abstract: Large language models have exhibited impressive performance across a broad range of downstream tasks in natural language processing. However, how a language model predicts the next token and generates content is not generally understandable by humans. Furthermore, these models often make errors in prediction and reasoning, known as hallucinations. These errors underscore the urgent need to better understand and interpret the intricate inner workings of language models and how they generate predictive outputs. Motivated by this gap, this paper investigates local explainability and mechanistic interpretability within Transformer-based large language models to foster trust in such models. In this regard, our paper aims to make three key contributions. First, we present a review of local explainability and mechanistic interpretability approaches and insights from relevant studies in the literature. Furthermore, we describe experimental studies on explainability and reasoning with large language models in two critical domains -- healthcare and autonomous driving -- and analyze the trust implications of such explanations for explanation receivers. Finally, we summarize current unaddressed issues in the evolving landscape of LLM explainability and outline the opportunities, critical challenges, and future directions toward generating human-aligned, trustworthy LLM explanations.